We sort words without thinking. Machines can't. They learn to draw boundaries and find themes: spam or not, tickets by topic. Use labels when you need decisions and clusters when you need discovery. Start there. Patterns come first, meaning follows.
How Machines Sort and Cluster Text to Find Meaning
You are staring at an overflowing inbox. Your brain, without much effort, draws fast, almost invisible lines: work, junk, family, I’ll deal with that later. Every day we sort the mess of language into buckets, sometimes without even noticing.
Now set aside your intuition. Imagine a machine faced with the same flood of words. No lived experience. No gut instinct. Just text, a torrent of letters with no shape or story. How does it carve any order from chaos?
This is where the first hints of machine understanding begin. Before an AI can answer questions or write a passable essay, it learns to draw boundaries. It divides language into categories and themes, sometimes by following rules we give it, sometimes by tracing patterns it finds on its own.
Machines do not read. They sort first, then they guess at meaning.
The story starts with naming. Spam or not spam. Positive or negative. Sports or politics. We hand over examples, and the model learns to separate apples from oranges. But language rarely arrives in neat boxes. Often all you have is a sea of words and a hope that something coherent will emerge. Then the machine must play detective, sniffing out clusters of meaning and surfacing themes no one labeled.
Two paths, then. Label by instruction, or discover by pattern. Both are attempts, clumsy at first and then surprisingly competent, to impose structure on noisy human language.
How Machines Learn to Label Text
Open your inbox, and almost without thinking, you know which emails are junk. Maybe it is the all-caps “WIN MONEY NOW!” or a strange link to nowhere. Our brains are old pros at this. How do you teach a machine to make the same snap judgment?
Early systems were blunt. The first spam filters did not really read your email. They counted words with no context. If the tally sheet hit enough suspicious terms like “prize,” “free,” or “money,” the message went to spam. This was the bag-of-words model. Take a pile of tokens, ignore order, and hope the right words tip the scale.
This method was simple and cheap and sometimes shockingly effective. Paul Graham made it famous with A Plan for Spam, showing that a naive Bayes classifier paired with word counts could filter inboxes faster than any human. But there were cracks. Swap “I love cats” with “I do not love cats,” and the model might miss the difference. Negation, irony, and even basic context slipped through.
So how do you build something sharper, something that does more than count? Start with TF-IDF (Term Frequency-Inverse Document Frequency). It asks two questions: how common is a word in this document, and how rare is it across the whole collection? Filler words like “the” or “and” fade, while rare, telling words such as “merger,” “lunar,” or “pandemic” stand out. Represent each document as a vector of these scores, then train a simple classifier like naive Bayes or logistic regression. The boundaries you get are usually cleaner.
Counting words was a start. Context is what makes it useful.
For many everyday problems, this recipe still works. News sorting, basic sentiment analysis, and spam detection can all run fast without a GPU. Naive Bayes remains a favorite because it is efficient and surprisingly tough to beat on simple text tasks.
For example, imagine a news sorter. You feed in thousands of headlines tagged as sports, politics, or tech. The model builds a vocabulary. “Touchdown” and “stadium” point to sports. “Election” and “senate” signal politics. When a new article arrives, the system vectorizes it, weighs the evidence, and picks a label almost instantly. That is supervised classification in action.
Language kept evolving, and so did the tools. Handcrafted features started to feel quaint. Embeddings arrived. These are numbers that capture relationships in meaning. “King” and “queen” live close together in a learned geometry. Models like Word2Vec and GloVe gave us dense, pretrained vectors that you could plug into a simple classifier. Freeze the embeddings, add logistic regression, and you get strong results with very little training.
Next came transformers. Architectures like BERT and RoBERTa learn context, not just counts. You take a pretrained language model that has read a large slice of the internet and fine-tune it on your task. The results can be striking. Sentiment models that handle sarcasm. Spam filters that understand negation. Accuracy jumps even with limited labeled data.
No labels at all? You can still classify. Prompt a large model with a few examples and ask it to label new text. This is zero-shot or few-shot learning. It is like asking an expert who has read everything instead of training a rookie from scratch.
And the tooling is friendly. With Hugging Face Transformers, you can load a model and classify in a few lines:
from transformers import pipeline
classifier = pipeline("text-classification", model="distilbert-base-uncased-finetuned-sst-2-english")
result = classifier("I really enjoyed the movie!")
print(result)
# [{'label': 'POSITIVE', 'score': 0.99987626}]
Flow from tokenization and features or embeddings to classifier and predicted label
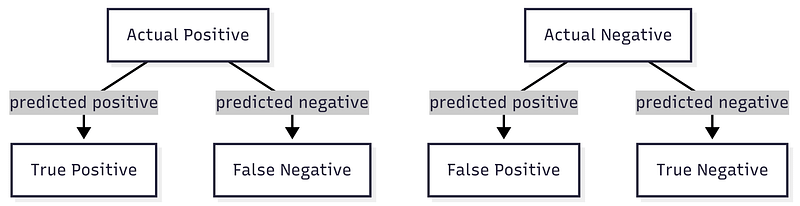
How do you know if your classifier is any good? Use a confusion matrix. It shows not just how often you are right, but the types of mistakes you make. False positives, false negatives, precision, and recall all sit in one grid. For a spam filter, you might accept a few false alarms, but you really want to catch as much spam as possible. The matrix keeps you honest.
Confusion matrix showing true and false positives and negatives with axis labels
Supervised classification is teaching by example. We point, we label, and we draw boundaries. The model learns, and with luck, it generalizes. What if you have no labels and still need structure? Then we turn to discovery.
Discovering Hidden Topics
Teaching a machine to label text is one thing. What if you do not have labels or even a clear idea of what you are looking for? Picture a stack of diaries or support tickets with no tags. You want themes to emerge on their own. Clustering and topic modeling let an AI discover structure in raw language.
Early attempts were simple. Turn each document into a TF-IDF vector, then run k-means or hierarchical clustering. Sometimes this worked. Sports articles were grouped together, and politics formed another group. Nuance was thin, and overlap was ignored. Hard boundaries, little context.
A better idea arrived with Latent Dirichlet Allocation, or LDA. Treat each document as a mixture of topics, and each topic as a distribution of words. Feed LDA a pile of text, and it surfaces topics that make intuitive sense. One topic might lean on “dog,” “cat,” “vet,” and “pet.” Another might push “credit,” “bank,” “loan,” and “account.” All of this happens without labels. LDA was a step toward discovery rather than instruction.
LDA has limits. It can produce junk topics, and it treats words as if their meaning never changes. “Bank” in a river and “bank” in finance sit in the same bucket. That is where embeddings changed the game. Models like BERT or Sentence Transformers create vectors that capture context. Two documents with different words but similar meanings land close to each other in a semantic space. Now you can cluster by meaning, not only by shared vocabulary.
Pipeline for topic discovery using embeddings, UMAP, or PCA for clustering, optional t-SNE for 2D visuals, then clustering and labeling
A common recipe looks like this:
Embed every document with a transformer model.
Reduce dimensions with UMAPor PCA for clustering. Use t-SNE for 2D visualization only.
Cluster in the reduced space. HDBSCAN can find clusters of different shapes and can leave outliers unassigned.
Label clusters by inspecting top terms, using c-TF-IDF, or asking a smaller model to summarize each group.
You can run this end-to-end with BERTopic. It wires together embeddings, reduction, clustering, and labeling. It also adds c-TF-IDF to produce cleaner keywords that truly distinguish each topic. HDBSCAN will often place stray items into an outlier bucket, usually labeled as -1. That is helpful in messy data, because not everything belongs somewhere neat.
Outliers are not mistakes. They are where the interesting work begins.
from bertopic import BERTopic
from hdbscan import HDBSCAN
docs = [
"The Apollo program put a man on the moon.",
"I loved the space exhibit at the science museum.",
"The bank raised its interest rates.",
"Cats and dogs are common pets."
]
topic_model = BERTopic(
embedding_model="all-MiniLM-L6-v2",
hdbscan_model=HDBSCAN(min_cluster_size=2, min_samples=1),
random_state=42
)
topics, probs = topic_model.fit_transform(docs)
# Overview of discovered topics
print(topic_model.get_topic_info())
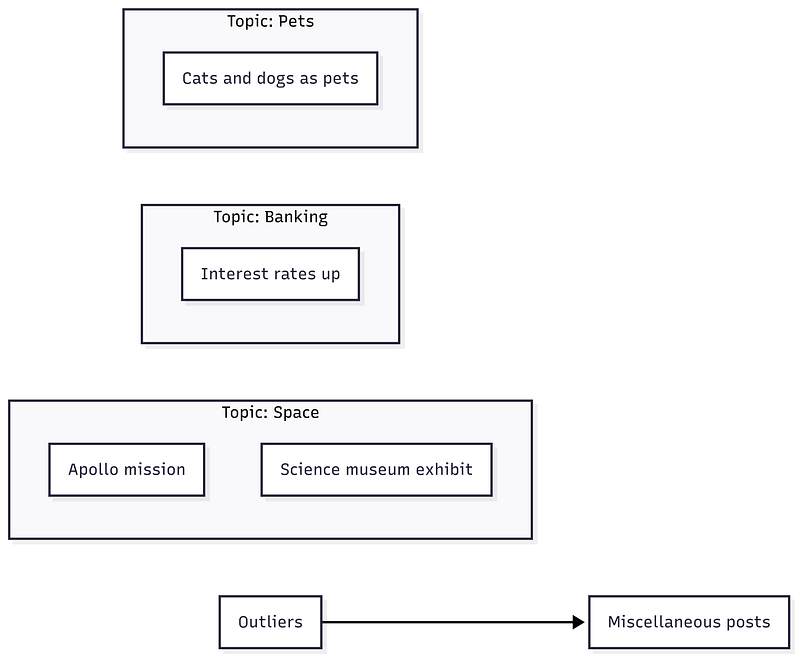
Consider the classic 20 Newsgroups dataset. Without labels, a modern pipeline can uncover clusters whose top words read like “windows, file, disk, software” for computing, or “Jesus, Bible, faith, Christian” for religion, or “space, orbit, launch, lunar” for NASA and space. Outliers fall to the -1 bucket. That is a feature, not a bug.
Conceptual 2D cluster map with several topics and an outlier group
Clustering is not a crystal ball. Results depend on your embeddings and your parameters. Too few clusters and themes blur together. Too many and you split hairs. Sometimes a model proposes a split that humans would not make. Human review still matters. Merge, split, or rename as needed.
Hybrid methods are now common. You can seed topic modeling with a few keywords to guide the outcome. You can also skip clustering and ask a capable model to assign labels directly with a prompt. The line between supervised and unsupervised grows thin. The goal stays the same. Give shape to text so that patterns, questions, and decisions come into view.
Why Sorting and Clustering Matter
What have we really taught these machines? Not how to read like a person. Not the kind of reading where you catch a joke or feel a line land. We taught them how to sort. We taught them how to draw boundaries and to notice clusters where there used to be only noise.
When a model flags spam, it is drawing a sharp line. When a topic model groups reviews, it is tracing soft borders around themes. One tool files language into drawers. The other sketches a map. Both turn chaos into shape.
It is not far from how we start as children. A parent points and names. The child notices patterns. Round things roll. Sharp things hurt. With time, the sorting becomes instinct.
Modern systems weave these methods together. Unsupervised pretraining builds general knowledge from raw text. Supervised learning tunes it for the task at hand. Hybrid workflows use discovery to suggest a taxonomy, then use labels to lock it in. Bit by bit, the model learns not only to produce words but also to respect structure and intent.
These steps matter. Sorting and clustering look simple, yet they are the foundation for everything else. A model that can separate a love poem from a legal brief is a model that can start to answer well. It can respond in the right voice and stay on the right track.
Use labels when you need decisions. Use clusters when you need discovery.
If you build with language, start here. Use classification when you need clear choices. Use clustering and topics when you need exploration. Review the results, merge or split as needed, and ask better questions the next round. The machine finds patterns. You decide what they mean.
Maybe that is the promise worth keeping. In a world overflowing with text, these tools help us notice what matters. They may never understand as we do. If they help us see order where we saw only noise, that is already useful.
V
Subscribe to our newsletter.
Become a subscriber receive the latest updates in your inbox.
You might also like
Aug 25
The End of the Magic Prompt
Good output is not a wish. It is systems work. We stitch steps into chains, add memory, let agents pick tools, and tune models until behavior matches intent. The magic prompt is over. Real craft is designing how the machine thinks, then teaching it.
6 min read
Aug 12
Prompt Engineering and the Illusion of Instruction
We think we’re giving orders. We’re steering a next-token engine. Prompts work when they mirror patterns the model has seen. Tiny phrasing changes flip outcomes. Guide with short roles, small examples, and simple formats. Verify. Cooperation, not command.
10 min read
Aug 11
What Makes a Senior Developer Senior?
Seniority isn’t a title. It’s how you work when it counts: choose the boring tool when it wins, ship with guardrails, teach without theater, cut complexity, and own outcomes after merge. Tradeoffs over tricks. Clarity over clever. Spotlight traded for team lift.
8 min read
Aug 06
Inside the Clockwork of an AI’s Mind
Ask a question, get a fluent answer. Under the hood, no insight, just a fast loop picking the next token, guided by attention and a tiny memory. See the gears, not a ghost. When you learn the strings, you know when to trust it and when to steer.
10 min read
Aug 02
Chopping Language, Weaving Meaning
Language models don’t read like we do. They slice text into tokens and map them to vectors. Meaning becomes pattern, not understanding. Learn the quirks of tokenization and embeddings to write tighter prompts, spot bias, and know what gets lost.







Member discussion