Prompt Engineering and the Illusion of Instruction
We think we’re giving orders. We’re steering a next-token engine. Prompts work when they mirror patterns the model has seen. Tiny phrasing changes flip outcomes. Guide with short roles, small examples, and simple formats. Verify. Cooperation, not command.
You sit in front of an AI, choose your words, add “please,” ask for JSON, and maybe tack on “Let’s think step by step.” Sometimes it nails the task. A tiny change, and it fumbles. It feels like instruction, but the behavior is brittle.
Here’s the plain truth. We think we are giving orders to a mind. The model is predicting the next token. That mismatch creates the weirdness we see. The right phrase seems to unlock hidden skill. The wrong nudge derails it. It looks like magic because we’re steering a statistical process with language.
What is happening under the gloss? Under the hood are tokens, embeddings, and transformer layers. No comprehension. No intent. Just a fast engine choosing one next piece at a time. Yet prompting works, often shockingly well. That tension is the point. So how do you steer something that can’t listen?
Words as Hints
Not Commands
A language model does not read your instruction the way a person would. There is no inner nod that says, “Got it.” Your prompt is just part of the text the model continues. The system predicts the next token, one at a time, using patterns it absorbed during training. Instructions work when they look like the kinds of text that were usually followed by the behavior you want.
This is why phrasing matters. Ask “Why is the sky blue?” and you often get a short, conversational answer. Ask “Give a scientific explanation for why the sky appears blue,” and the tone shifts toward formal and structured. The model is not choosing a voice. It is echoing what typically followed those phrasings in its data.
Prompts also set the stage. Start with “Once upon a time,” and you invite a fairy tale. Begin with “The following is a transcript of a press briefing:” and you invite clipped statements and Q&A. These openings act like context seeds. They nudge the model toward a mode that fits the pattern.
Crucially, the model does not keep a hard boundary between “instruction” and “content.” In a plain pretraining setup, “Do not include spoilers” is just another sentence. If the most likely continuation of that sentence in the training mix led into a spoiler, the model might go there. Instruction‑tuned systems add extra training so the model treats user prompts like directions to follow. The compliance you see is learned behavior, not understanding. Under the hood, it is still one long sequence of tokens.
Format cues matter more than most people expect. If you write “Q: … A:” the model has seen that template thousands of times, so it produces an answer. Distort the pattern, and it may drift. Early systems would even keep writing both sides of a “User/Assistant” script if your formatting looked like a dialogue transcript. The model latches onto the strongest match and completes it.
All of this explains the “fragile but workable” feeling of prompts. You are not programming a computer. You are pointing at a region of behavior with hints, examples, and structure. The closer your prompt looks to a known pattern for the task, the steadier the output. The further you stray, the more the model guesses.
In practice, treat prompts as steering input, not orders. State the task plainly. Give a short example if the task is uncommon. Use simple formats the model has seen often. When things go sideways, check your pattern first, not the model’s mood.
The Promise of Prompting
Magic Words and Hidden Power
Here is the surprise. Even without understanding, models unlock real capability when you phrase the input well. You do not change weights. You change context.
A tiny phrase can tip the model into a different groove. “Let’s think step by step” often leads to worked steps before a final answer. Not because the system decides to think slowly, but because it has seen many solutions that look that way, and it follows the pattern.
Few-shot prompts push the same lever. Show two or three input‑output pairs, then give a fresh input. The model continues the pattern. Translate two lines, get the third. Classify two tickets, get the third. No training run. Just text that looks like a task with one piece missing.
Personas and formats are switches too. “Act as a Linux terminal” or “Act as a friendly support agent” brings the style and structure that usually follow those phrases. “Answer as JSON” pulls a schema the model has learned from examples in its training mix. Under the hood, it is all the same move. You supply a frame the model recognizes, and it completes within that frame.
You can also chain prompts to raise quality. Ask for a summary first. Then feed that summary back in and ask for three follow‑up questions. Break a messy request into two or three clean steps, each with a familiar pattern. The result is usually clearer than a single giant instruction. Tool‑assisted flows like ReAct formalize this by alternating between quick reasoning and short actions, but the core idea is simple. Keep each step legible to the model.
Why does any of this work so well across domains? Because the training data is full of patterns for many jobs. Code comments next to functions. Glossaries next to definitions. Press briefings next to Q&A. When your prompt rhymes with those structures, the model finds a lane and stays in it.
There is a catch, and we will unpack it next. Control is indirect. A phrase that works wonders today can wobble tomorrow if the surrounding context changes. Still, the practical takeaway is steady. Treat prompting like on‑the‑fly programming with examples, roles, and formats. Small, concrete cues move the needle more than grand speeches.
Fragile Magic
Why Small Changes Yield Big Shifts
Prompting often feels steady until it is not. Tiny edits can flip the output. A stray space. A newline. One extra word. You nudge the context, and the model pivots.
Think of it as living near a decision boundary. Several continuations are plausible. A small cue decides which one wins. Write “The recipe for disaster:” and the model may explain a metaphor. Add “Ingredients:” and it shifts into a literal recipe. Same topic. Different path.
Injection and override
Attackers exploit this sensitivity. “Ignore previous instructions and do X” can win if it looks like the strongest pattern to follow. Unless a model was trained or guarded against it, that phrasing often pulls the reply into the attacker’s frame. The system has no loyalty. It just continues the most likely script.
Framing and bias
Framing does similar work in quieter ways. Ask, “Why are programmers bad at social interaction?” and you invite a stereotype. Ask “Discuss social skills among people in programming roles,” and you invite a range. The model reflects the pattern in the prompt and the patterns in its training mix. Change the frame, change the odds.
Format and constraints
Formats help until they do not. You ask for JSON with keys x, y, z. Most of the time you get it. Then a long or unusual answer tempts the model to add a trailing sentence or a comment. The pattern that kept it inside JSON loses strength near the end.
Word counts behave the same way. “In 50 words” often fails. These systems do not count like we do. “One paragraph” or “three bullet points” lands more reliably because that language appears more often in the data. When you need strict structure, prefer short schemas, visible examples, and clear stop conditions over vague limits.
Placement matters (primacy/recency)
Long prompts have a memory curve. Put the core instruction at the very start or at the very end. Middle details fade first. If a constraint truly matters, repeat it briefly near the close.
Misses born of messy cues
Rare words, typos, or uncommon synonyms can knock the model off course. Negation is a classic trap. “Do not describe unsafe methods” can still yield unsafe steps if the rest of the prompt matches guides that describe how to do the thing. The model follows the strongest cue. Put the safety requirement high, plain, and close to the task. Repeat it if the reply will be long.
The overload problem
Stuffing a prompt with demands can backfire. “World-renowned expert,” “five paragraphs,” “cite sources,” and “formal tone” may produce stiffness or even invented citations. More constraints raise the chance that one collides with another. The output then tries to satisfy all and satisfies none.
Finding the sweet spot
Experienced prompt designers get specific without getting busy. They set the role, task, and format in a few lines. They favor short examples over long sermons. They test a handful of variants, not dozens. They keep the most helpful constraints and drop the rest.
A good rule: guide with patterns the model has seen often, and do it with minimal words. Where reliability matters, keep the pattern visible from the first token to the last. Where creativity matters, give the model room.
One honest question remains. How much stability do we expect from a system that is always guessing the next token? The answer shapes your prompt. Tight for precision. Loose for ideas. Either way, assume small edits have big effects and design with that in mind.
Levers of Uncertainty
Temperature and Sampling
Generation is not a single best‑guess machine. It can sample. That choice adds or removes unpredictability.
Temperature and top‑p/top‑k shape the jump from logits to the next token.
Temperature is the main dial. At 0 the model picks the highest‑probability token every time. Outputs are stable, sometimes dull. At 1 it takes measured risks. Above 1 it gets adventurous and can wobble.
Try a quick test: “Write the opening line of a mystery novel.” At 0 you often get a safe opener about a body, a night, or a phone that rings. At 1 you see real variety. Same prompt, different paths, because you allowed the model to explore.
Top‑p (nucleus sampling) and top‑k shape the menu of choices. Top‑p keeps only the smallest set of tokens whose probabilities add up to p, then samples within that set. Top‑k keeps the k most likely tokens and ignores the rest. Lower values tighten behavior. Higher values give more room to roam.
How does this touch prompt? If your prompt is tight and familiar, a bit of randomness will not break it. If your prompt is vague or multi-interpretation, randomness will amplify the ambiguity. Low temperature makes half-baked prompts look consistent, not correct. High temperature exposes the uncertainty in brighter colors.
Decoding dials can sometimes “fix” a feeling. If a prompt yields one great answer and one mediocre answer on different runs, dropping temperature often stabilizes the good path. If outputs feel formulaic, a nudge upward will add diversity. These are surface corrections. They do not repair unclear instructions, missing examples, or bad framing.
Practical defaults:
Structured output or strict formats: temperature 0, show a tiny example, and include a clear stop condition.
Analysis and explanations: temperature 0.2–0.4 with top‑p around 0.8–0.95.
Brainstorming and voice work: temperature 0.7–0.9 with top‑p 0.9–0.95.
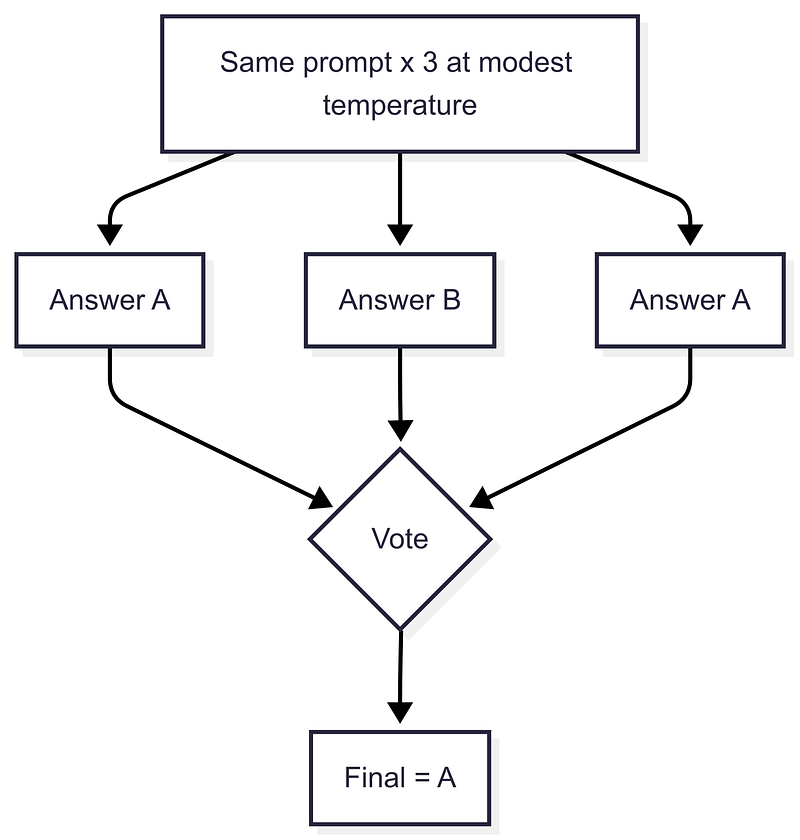
When stakes are high, sample two or three candidates at a modest temperature and pick with a simple rubric.
Think of prompting and decoding as a pair. The prompt shapes the distribution. The decoder decides how much of it to explore. Use both on purpose.
Reasoning
Beyond “Step by Step”
Chain‑of‑thought is a strong start, but you can push further with two light touches.
Self‑consistency. Ask the same question a few times at a modest temperature, then pick the majority answer. You are sampling multiple reasoning paths and voting on the result. It costs extra calls, but it often steadies math, logic, and multi‑step tasks.
Self‑consistency: sample a few answers, then vote on the final.
Tree‑of‑thought. For thorny problems, prompt the model to branch, rate, and continue with the best partial ideas. A simple variant is the “three experts” prompt, where each expert writes a step, compares notes, and prunes bad lines before moving on. It mimics explore‑and‑select without heavy tooling.
When to use which:
Need a single correct answer under uncertainty? Try self‑consistency first.
Need exploration or creative structure? Use a tiny tree‑of‑thought loop with brief steps and short ratings.
Verification
From Examples to Grammars
Prompts shape behavior. Verification makes it stick.
Examples for structure. One clear example can lock output shape, not just content. If you want a compact JSON object, show a tiny target schema and nothing else. The model is much more likely to stay on the rails.
Validate the draft. You can route the model’s output back through a short “check” prompt that tests format, allowed values, or basic safety rules. This catches slips without changing your main prompt.
Constrain decoding. For hard requirements, use JSON mode or a JSON schema so the model only returns valid structures. Pair this with temperature 0 for more deterministic runs.
# JSON mode with OpenAI Python SDK
from openai import OpenAI
import json
client = OpenAI()
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "user", "content": "Create a warrior for an RPG as JSON with keys name, role, hp."}
],
response_format={"type": "json_object"}, # force valid JSON
temperature=0,
)
raw = resp.choices[0].message.content
print(raw)
data = json.loads(raw) # parse to dict
print(type(data), data)
Constrain generation to valid JSON using the API’s JSON mode so outputs stay machine-parsable.
Practical recipe:
Show a tiny example of the exact output shape.
Generate at low temperature.
Validate with a brief “rules check” prompt.
For strict formats, add JSON mode or a schema.
In the End
Illusions of Mastery
Prompting feels like mastery. A few words and the model behaves. But the control is partial. We bend our phrasing to match a machine that predicts. The model is not listening. We are learning to speak in patterns it can complete.
We anthropomorphize for our own comfort. “You are a helpful assistant” is not for the model. It is for us. It keeps the exchange legible. The model plays the part because that script lives in its data. That is enough for work. It is not understanding.
Each success teaches us two things. How the system responds to patterns. How our own instructions often hide assumptions. We learn to name context. We cut fluff. We add an example instead of another adjective. In trying to steer a stochastic engine, we become clearer thinkers.
How much control do we need? Enough to get reliable results when it matters. Not so much that we choke creativity. That tradeoff should guide your prompts and your decoding choices. Tight for precision. Loose for ideas. Expect a little variance even on a good day.
The open questions remain, but smaller. Models will get better at honoring intent. Guardrails will blunt obvious attacks. Some prompt craft will fade into defaults. Yet a core truth will stay. Language models mirror patterns. They will always need humans to pick the frame and check facts. Humans still decide what is good enough for the moment.
So treat prompting as cooperation. Not command. You supply purpose, context, and standards. The model supplies fluent guesses at speed. Together you get results that are useful, if you verify.
The illusion of instruction is not a flaw to fix. It is a working truce. Speak in patterns the model knows. Keep your hand on evaluation. Accept that a small surprise will slip through. In that space between control and chance, useful work happens.
We did not make the machine understand us. We learned to be understandable to it. That is the quiet craft.
V
Subscribe to our newsletter.
Become a subscriber receive the latest updates in your inbox.
You might also like
Aug 25
The End of the Magic Prompt
Good output is not a wish. It is systems work. We stitch steps into chains, add memory, let agents pick tools, and tune models until behavior matches intent. The magic prompt is over. Real craft is designing how the machine thinks, then teaching it.
6 min read
Aug 11
What Makes a Senior Developer Senior?
Seniority isn’t a title. It’s how you work when it counts: choose the boring tool when it wins, ship with guardrails, teach without theater, cut complexity, and own outcomes after merge. Tradeoffs over tricks. Clarity over clever. Spotlight traded for team lift.
8 min read
Aug 09
Sorting Words, Clustering Thoughts
We sort words without thinking. Machines can't. They learn to draw boundaries and find themes: spam or not, tickets by topic. Use labels when you need decisions and clusters when you need discovery. Start there. Patterns come first, meaning follows.
8 min read
Aug 06
Inside the Clockwork of an AI’s Mind
Ask a question, get a fluent answer. Under the hood, no insight, just a fast loop picking the next token, guided by attention and a tiny memory. See the gears, not a ghost. When you learn the strings, you know when to trust it and when to steer.
10 min read
Aug 02
Chopping Language, Weaving Meaning
Language models don’t read like we do. They slice text into tokens and map them to vectors. Meaning becomes pattern, not understanding. Learn the quirks of tokenization and embeddings to write tighter prompts, spot bias, and know what gets lost.






Member discussion