Ask a question, get a fluent answer. Under the hood, no insight, just a fast loop picking the next token, guided by attention and a tiny memory. See the gears, not a ghost. When you learn the strings, you know when to trust it and when to steer.
When you send a prompt to ChatGPT, it can feel like stage magic. A question goes in; a polished answer comes out, almost instantly. But if you peel back the curtain, there’s no single flash of brilliance. What you find instead is a relentless, mechanical grind. Large language models don’t think in paragraphs or sentences. They build their replies one token at a time. Sometimes a token is a whole word, sometimes just a fragment, or even a stray comma. This is the hidden machinery: an AI that writes not in sweeping thoughts, but in tiny steps, each chosen and then immediately forgotten.
Peeking inside, the process is at once more mechanical and weirder than most expect. Yet when you understand what’s happening, the real magic isn’t lost. If anything, it’s more impressive. There’s no illusion, only a very fast, very stubborn little engine, putting words together in real time.
Given everything so far, what comes next?
One Token at a Time
The Autoregressive Dance
A large language model doesn’t map out entire sentences in advance. It works more like a nervous improv comic: look at the prompt and everything that’s already written, then guess at high speed what token should come next. Type it out. Glance again at the new total, and make another guess. And again. This looping, token-by-token process is what’s called autoregressive generation.
Each guess happens in a blink. The model is always asking, “Given everything so far, what comes next?” There’s no master plan, just relentless, local choices. That’s why AI responses feel like a stream, trickling out piece by piece. It’s also why these systems can sometimes lose the thread or repeat themselves: they’re building the path as they walk, with no outline, only the road just behind.
Here’s how the process loops: with each step, the model adds its new token to the prompt and runs through the stack again. Until it’s finished. (Image by Author)
The Transformer Stack
Layers of Thought
How does a language model choose the next token? The answer lies in a tall stack of neural network layers called Transformer blocks. Think of each block as a filter: the data goes in, gets reshaped a little, then moves to the next. A big model may have dozens of these layers, each nudging the meaning, sharpening the context, or picking up on patterns.
It all starts with turning your prompt into numbers, with tokens mapped into mathematical vectors. These vectors travel up the stack, block by block, each one twisting the data in its own learned way. By the end, the model has built a rich, compressed summary of everything you’ve written so far.
At the top, a final component called the language model head takes over. Its job: translate the last layer’s output into a giant set of scores, one for every possible token in its vocabulary. If there are 50,000 tokens, it produces 50,000 guesses for what comes next. The software then picks one (using rules we’ll get to), and the whole process starts again, with the new token added to the running history.
At each step, your input flows from the tokenizer through a stack of processing blocks, all the way up to the model head, which decides what comes next. (Image by Author)
There’s no secret memory from one step to the next. Every time, the model recomputes everything from scratch, using only the prompt and everything it’s already written. This may sound wasteful, but it keeps the model tightly focused. No detail gets lost, because the system reprocesses all context every time.
Attention
How the Model Focuses on Context
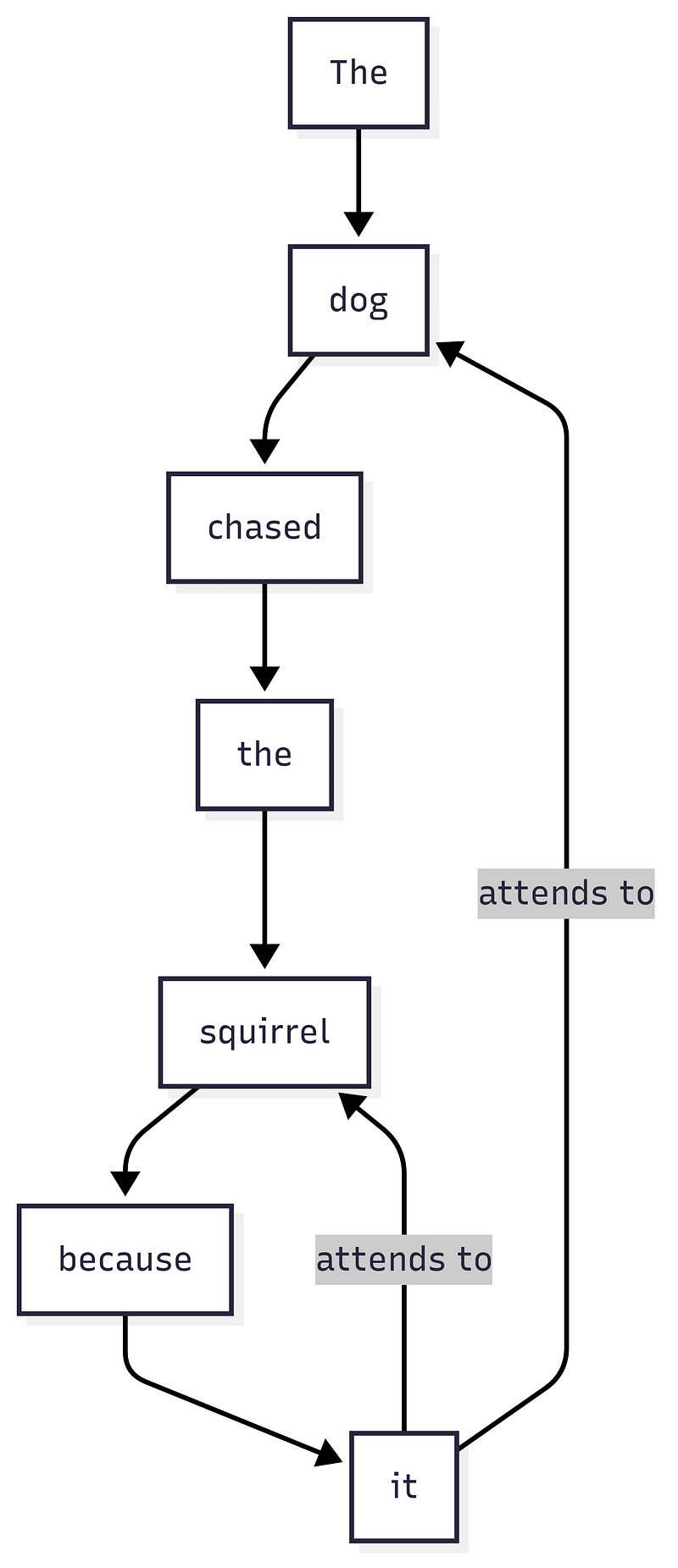
Inside every Transformer block, you’ll find something called self-attention. This is the model’s way of staying aware of context. Instead of looking at each word in isolation, self-attention lets every token scan the whole prompt and decide what matters most.
Self-attention lets each token reach back and draw meaning from others. For example, the ‘it’ at the end of this sentence can look at both ‘dog’ and ‘squirrel’ to decide what it refers to. (Image by Author)
Take a classic ambiguity from everyday language. Suppose you’re reading: “The trophy didn’t fit in the suitcase because it was too small.” Instinctively, you know “it” points to the trophy. For a model, self-attention makes this leap possible. Each token sweeps a kind of mathematical spotlight across the sentence, searching for the clues it needs. Here, “it” will end up weighing “trophy” more heavily than “suitcase.”
This scanning doesn’t happen just once. It repeats in every layer. Early on, the model might catch grammar or syntax, but as it moves up, it starts picking up on themes, facts, and relationships. By the top, you have a dense web: who did what, what refers to what, and which details echo or matter.
Older models read language like beads on a string, only seeing what came right before. Transformers with attention see a whole web, connections that jump backward and forward, making sense of references and holding a topic together. In a way, attention is how the model fakes memory. It isn’t storing facts, but it keeps finding the right ones to bring forward just when the context calls for it.
Feedforward Networks
The Knowledge Repository
After attention has sorted out which details matter, the feedforward network steps in. Think of it as a specialized processor. It takes each token, now flavored by context, and decides how to transform it for the next round.
Technically, it’s just a couple of matrix multiplications and an activation function, repeated for every position in the text. But what matters is what these layers have learned. During training, the feedforward blocks soak up patterns, facts, and common sense from the sea of language they’ve seen. If attention asks, “What’s important right now?”, the feedforward network answers, “And what should we do about it?”
This is where much of the model’s knowledge lives. It’s not as trivia or facts, but as probabilities and associations, woven into billions of tiny weights. Stack up dozens of these attention-plus-feedforward layers, and you get a ladder: the early rungs spot grammar and phrases, and the later ones manage tone, logic, or style.
By the end, every token carries a mix of local context and the distilled wisdom of all the text the model has absorbed. When it’s time to predict the next word, the LM head looks at these transformed tokens and makes its call.
In short: attention finds connections, and feedforward networks decide how to use them. The magic happens in the partnership.
Decoding Strategies
Choosing the Next Word
Sometimes, picking the next word is straightforward. The model lines up every possible token and scores them all. The simplest move is greedy decoding. Just take the highest score, no second-guessing. This approach works perfectly for facts. If you ask for the capital of France, you get Paris. But if you use it for open-ended writing, you end up with answers that are flat and repetitive. The safest option almost never surprises you.
To shake things up, most systems add a dose of randomness. Imagine a roulette wheel, where bigger probabilities claim more space. The model spins, and whichever token it lands on becomes the next word. This is sampling, and you can adjust how wild it gets with a setting called temperature. Low temperature means cautious, almost always sticking to the obvious. Turn up the heat, and the model gets bolder, sometimes picking the second or third best, even the occasional oddball.
There are hybrids, too. Top-k sampling picks from only the most likely k tokens. Nucleus sampling (top-p) collects just enough top tokens to reach, say, 95% of the total probability, then samples among them. This stops the model from drifting into pure nonsense but still keeps things lively.
The way you tune these choices shapes the model’s personality. Set everything to safe, and you get careful, plain answers. Open the door to more randomness, and the AI starts to riff, sometimes brilliantly, sometimes off the rails. Getting this balance right is as much art as engineering.
The Limits of Memory
Context Windows
Even the most advanced language models have a hard limit on memory. This is the context window, the maximum number of tokens the model can handle at once. For GPT-3, it’s about 2,000; newer models stretch to 8,000, 32,000, or more. Every prompt and every reply must fit inside that space. Go over the limit, and the earliest tokens simply fall away, forgotten.
Think of it like trying to read a long story through a mail slot: you can only see so much at a time, and once something scrolls out of view, it’s gone. The model can’t reach back. So in long chats or when working on huge documents, it loses track of anything that slips past the window, unless you repeat yourself or the system summarizes and feeds back the highlights.
Why not give it infinite memory? Because the cost explodes. Transformers compare every token to every other token, so doubling the window makes things four times slower and heavier. Researchers are chasing bigger windows, but for now, every session is a juggling act. You have to choose what to keep, what to trim, and how to fit the right details inside a tight space.
A model’s memory isn’t like ours. It doesn’t remember what mattered. It remembers only what’s in front of it right now. If you want it to recall something from earlier, you have to mention it again or risk watching it vanish, goldfish-like, with every new turn.
Under the Hood
Speed and Efficiency Tricks
The original Transformer design was a breakthrough, but the field keeps pushing for more speed and efficiency. Many of the best improvements happen behind the scenes, with small tweaks to the internals that make these models faster and more scalable while keeping the foundation intact.
Take FlashAttention, for example. Standard attention involves shuffling huge blocks of numbers around in memory, which can seriously slow things down, especially for long prompts. FlashAttention changes this by running calculations right where the data is stored, saving time and letting the model produce the same answers, just faster.
There’s more. Transformers use “attention heads,” which act like several spotlights working in parallel, each searching for different patterns or connections in the data. In the original setup, every head kept its own set of clues to check. That approach works, but it uses a lot of memory. Multi-query attention solves this by letting all heads share the same clues. It saves resources, though sometimes the heads become too similar. Grouped-query attention is a middle ground: a few groups each keep their own clues, so the model keeps some diversity but uses less memory. This approach has become standard in newer models, including Llama-2 and beyond.
Researchers have also explored local and sparse attention as ways to help the model focus on just a small subset of previous tokens, rather than every single one in the prompt. Think of it like reading a long novel, but when you need to recall something, you only reread the last few pages instead of starting from the beginning. Some models, like GPT-3, blend both strategies by alternating layers: some see the whole prompt, while others focus just on a local stretch of recent text. This trade-off keeps generation high-quality even for long passages, while also making everything faster.
What about word order? Early models simply stamped every token with its absolute position: first, second, third, and so on. That worked well enough, but once prompts got longer or the context became more flexible, it started to fall short. A newer method, called rotary positional embeddings (RoPE), rotates each token’s vector by a small angle based on its position in the sequence. The effect is a kind of mathematical dance that lets the model sense both distance and order, almost like swapping out a rigid ruler for a flexible tape measure.
None of these tricks change the heart of the Transformer. Together, though, they allow today’s models to train on much more data, handle much longer inputs, and serve far more people at once. The magic of a language model isn’t a single discovery. It is the result of a whole toolbox of clever engineering working together.
In the End
Gears, Magic, and What It All Means
Pull back, and the inside of a large language model looks almost comically mechanical. You find rows of numbers, tangled matrices, and loops that spit out tokens one by one. There’s no spark of understanding and no sudden “aha” moment. What you see is an engine grinding through math. Yet from this machinery, something unexpected appears. The model produces paragraphs, arguments, and stories that sometimes make you pause and wonder. How does that even happen?
Looking at the mechanism, you can feel two things at once. On one hand, it’s grounding. The model is not “thinking” the way humans do. It is matching patterns, splicing together fragments of text it has seen before. There is no wisdom or world behind its words. Knowing that, you start to approach every answer with a healthy dose of skepticism. You learn to ask better questions, steer the output, and notice when it wanders off course.
But the sense of wonder does not disappear. If anything, it gets sharper. Is this really all it takes? Layer after layer of matrix math, running fast enough on enough data, and suddenly the system can mimic understanding. It is humbling to realize how much of language, and maybe even thought itself, is structure and habit, not deep comprehension. Yet every clever tweak and every small improvement opens up new possibilities. The craft is far from finished.
Maybe the biggest surprise, looking inside an LLM, is what it reveals about us. These systems reflect us back to ourselves. They echo our habits and biases, our clichés, and our creative leaps. They remind us that words can carry meaning even if no one truly “knows” what they mean. At its best, an LLM can mirror the music of language, but it cannot capture its soul.
So next time an AI gives you an answer that seems almost too good, try to picture the gears at work. Tokens pass through layer after layer, context shrinks to fit the model’s memory, and each word is chosen with just a bit of randomness. There is no ghost in the machine. What you are seeing is a complicated puppet show. Yet understanding the strings behind the act does not spoil the magic. If anything, it helps you decide when to marvel, when to question, and how to use this tool wisely.
The prompt is still in your hands. The story is yours to write.
V
Subscribe to our newsletter.
Become a subscriber receive the latest updates in your inbox.
You might also like
Aug 25
The End of the Magic Prompt
Good output is not a wish. It is systems work. We stitch steps into chains, add memory, let agents pick tools, and tune models until behavior matches intent. The magic prompt is over. Real craft is designing how the machine thinks, then teaching it.
6 min read
Aug 12
Prompt Engineering and the Illusion of Instruction
We think we’re giving orders. We’re steering a next-token engine. Prompts work when they mirror patterns the model has seen. Tiny phrasing changes flip outcomes. Guide with short roles, small examples, and simple formats. Verify. Cooperation, not command.
10 min read
Aug 11
What Makes a Senior Developer Senior?
Seniority isn’t a title. It’s how you work when it counts: choose the boring tool when it wins, ship with guardrails, teach without theater, cut complexity, and own outcomes after merge. Tradeoffs over tricks. Clarity over clever. Spotlight traded for team lift.
8 min read
Aug 09
Sorting Words, Clustering Thoughts
We sort words without thinking. Machines can't. They learn to draw boundaries and find themes: spam or not, tickets by topic. Use labels when you need decisions and clusters when you need discovery. Start there. Patterns come first, meaning follows.
8 min read
Aug 02
Chopping Language, Weaving Meaning
Language models don’t read like we do. They slice text into tokens and map them to vectors. Meaning becomes pattern, not understanding. Learn the quirks of tokenization and embeddings to write tighter prompts, spot bias, and know what gets lost.







Member discussion