Language models don’t read like we do. They slice text into tokens and map them to vectors. Meaning becomes pattern, not understanding. Learn the quirks of tokenization and embeddings to write tighter prompts, spot bias, and know what gets lost.
When you chat with an AI like GPT-4, it isn’t reading your words the way you might expect. Instead, it’s slicing language into tiny pieces and mapping those pieces onto a mathematical space. In this hidden process—tokenization and embedding—lies both the magic of machine mimicry and the clues to what gets lost in translation.
Language in Pieces
How Machines Read Text
There’s a moment, equal parts wonder and mild letdown, when you realize large language models don’t see sentences the way you do. It’s like watching a pianist’s hands glide over keys until you look inside and find a hidden machine chopping the melody into raw notes before the music ever starts. That’s what a language model does to your words. It doesn’t hear your whole message. Instead, it breaks everything down into tokens, those scattered notes of language. If you’ve watched ChatGPT spit out a reply, piece by piece, you’re glimpsing this machinery in real time. Each answer is stitched together one token at a time. Not in broad strokes, but in fragments.
But what exactly is a token? Strip away the jargon, and it’s just a chunk of text. Sometimes it’s a whole word like "Hello". Sometimes it's only part of a word, as with "##ing". Sometimes it's just a stray character or bit of punctuation. The tokenizer doesn’t care. It’s a relentless butcher, slicing your input wherever it pleases.
Try feeding GPT the phrase "Hello World!". Here's what the model actually "sees":
How a language model “sees” your words: from raw text, to tokens, to numeric IDs, to dense embedding vectors—ready for computation. Every step strips away the original form but builds the foundation for the model’s statistical magic.
import tiktoken
enc = tiktoken.get_encoding("gpt2")
tokens = enc.encode("Hello World !")
print(tokens) # e.g. [15496, 2159, 5145]
print([enc.decode([t]) for t in tokens])
# Outputs: ['Hello', ' World', ' !']
That simple line "Hello World!" splits into three tokens: "Hello", " World" (notice the space clings to the front), and " !". Each one gets its own number, a token ID. The model doesn’t see "Hello" as a greeting. All it knows is 15496, 2159, 5145. Before a single neuron fires, your text has vanished, replaced by a string of numbers. Even spaces and punctuation earn their own IDs. Under the hood, every LLM API transmutes your input into something like the machine’s private Morse code.
Why go to all this trouble? Neural networks can’t think in words or letters. They need numbers, and tokens are our bridge. It’s not so different from translating English into Morse code or ASCII. The message remains, but now it’s all dots, dashes, or digital pulses.
Word-Level, Subword, and Character Tokenization
and Tradeoffs
The earliest language models were blunt instruments. They just split text wherever they saw a space or a punctuation mark. That’s word-level tokenization: every word gets its own token, as does every period or comma. Simple, almost naive. "I love pizza." becomes ["I", "love", "pizza", "."]. Easy for us to follow, but hard for machines to keep up.
Here’s why: if the model bumps into a word it hasn’t seen, say a typo or some internet slang, it’s stumped. In early word-level models like BERT, it would toss up an [UNK] (unknown) token and give up. But in modern models like GPT-3 and GPT-4, there’s no [UNK] token; instead, the word gets broken down into smaller chunks, so nothing is ever truly “unknown.” With word-level tokenization, every new word bloats the vocabulary. "Apology", "apologize", "apologizing"—each is separate, eating memory, and there’s still no guarantee you’ll catch tomorrow’s meme or next week’s misspelling. Word-level tokenization made the first generation of language models fragile and forgetful.
So engineers found a clever middle ground: subword tokenization. Rather than memorize every word, the model learns common pieces of words. The word "tokenization" might split into ["Token", "ization"]; "happiness" into ["h", "appiness"]. It’s mix-and-match. These pieces come from sifting huge piles of real text and noticing what fragments show up again and again. The result is a custom toolkit of “subwords,” not so broad that you miss a new word and not so fine that you drown in single letters.
Suddenly, the model isn’t baffled by "Uberization" or "hyperlooping". If the tokenizer has never seen the word, it just snaps it into familiar chunks. No more [UNK], fewer missed jokes. Systems like BPE, WordPiece, and SentencePiece, names you’ll see in any modern LLM, live in this Goldilocks zone. It’s the default in GPT, BERT, and their many offspring.
And then there’s the extreme approach: character-level or byte-level tokenization. Here, every letter or byte is a token. Vocabulary shrinks to the basics (the alphabet, or 256 bytes). Nothing is truly “unknown.” If all else fails, the model spells out a word, emoji, or weird symbol, piece by piece. But there’s a trade-off: with character-level tokenization, a single word like "extraordinary" becomes a parade of 13 tokens. Whole paragraphs balloon. Since every model has a limited memory (the “context window”), this kind of granularity can turn a story into a crowd scene and crowd out what matters.
The upshot? Picking a tokenization scheme is a balancing act between vocabulary bloat, handling the weirdness of real language, and squeezing as much meaning as possible into each model’s limited attention span. Change the method, the training data, or the intended language, and you get a different dialect. A different machine “accent.” OpenAI’s GPT-3 tokenizer, for example, used around 50,000 subword tokens (plus bytes for Unicode weirdness), while GPT-4’s cl100k_base packs even more into every slot. Smarter tokenization lets a model cram longer essays, emails, or code files into a single breath.
Tokenization Quirks, Dialects, and Practical Consequences
Here’s where things get weird. Each model speaks its own dialect of token language, and the quirks can trip up even seasoned engineers.
Spaces, for example, are sneaky. Some tokenizers, like GPT’s, often treat a leading space as part of the next token. So " Hello" and "Hello" are totally different as far as the model’s concerned. You might see "NewYork" become ["New", "York"] but "New York" split into [" New", "York"], with that stray space dragging along like toilet paper stuck to a shoe. Punctuation is just as tricky: "!?" might become two tokens, or three, depending on the context.
And because these vocabularies are learned from messy, real-world data, they come with their own set of artifacts. GPT-2’s tokenizer, for instance, had oddballs like "<|endoftext|>" to mark stopping points, and an accidental Easter egg, the famous "SolidGoldMagikarp" token, left over from a random text fragment that wormed its way into the training set.
Why does any of this matter? Because if you’re writing prompts, counting tokens, or debugging odd model outputs, the quirks and dialects explain why things sometimes go sideways. Ever have ChatGPT split a name in half or count spaces as if they’re words? That’s the tokenization showing through. Models like GPT-3 and GPT-4 even disagree on token counts for the same input, thanks to their slightly different vocabularies. A prompt that fits in one model might get chopped in another, with strange results.
If you want to work with LLMs and not against them, you have to learn a little of their secret language: the inside jokes, the misshapen words, and the invisible spaces. Once you see these quirks, the model’s odd behaviors start making more sense. Annoying? Sure. But also, a glimpse into the strange dialect spoken by your AI collaborator.
From Tokens to Embeddings
How Machines Assign Meaning
So, you’ve got a string of token IDs, maybe [15496, 2159, 5145] for "Hello World!". What now? The machine still doesn’t “see” words. Instead, it needs to give each token some kind of meaning it can work with. That’s where embeddings come in.
Try to imagine a giant, abandoned library, the kind with dust motes in the sunlight and card catalogs that go on forever. Every token ID is just a pointer to a card. On that card, instead of a definition, you’ll find a long line of numbers, its unique fingerprint. These fingerprints are the embeddings. Sometimes there are hundreds, sometimes thousands of them. Each one a coordinate that pins this token somewhere inside a vast, secret, high-dimensional universe.
But this isn’t random. When the model grabs the "Hello" card, it’s pulling out a point that lives near other greetings, or proper names, or whatever the training data found nearby. "World" sits in its own neighborhood. The fascinating trick is that the distance and direction between these points actually reflect meaning. That’s the model’s way of grouping related ideas, clustering what belongs together, and separating what doesn’t.
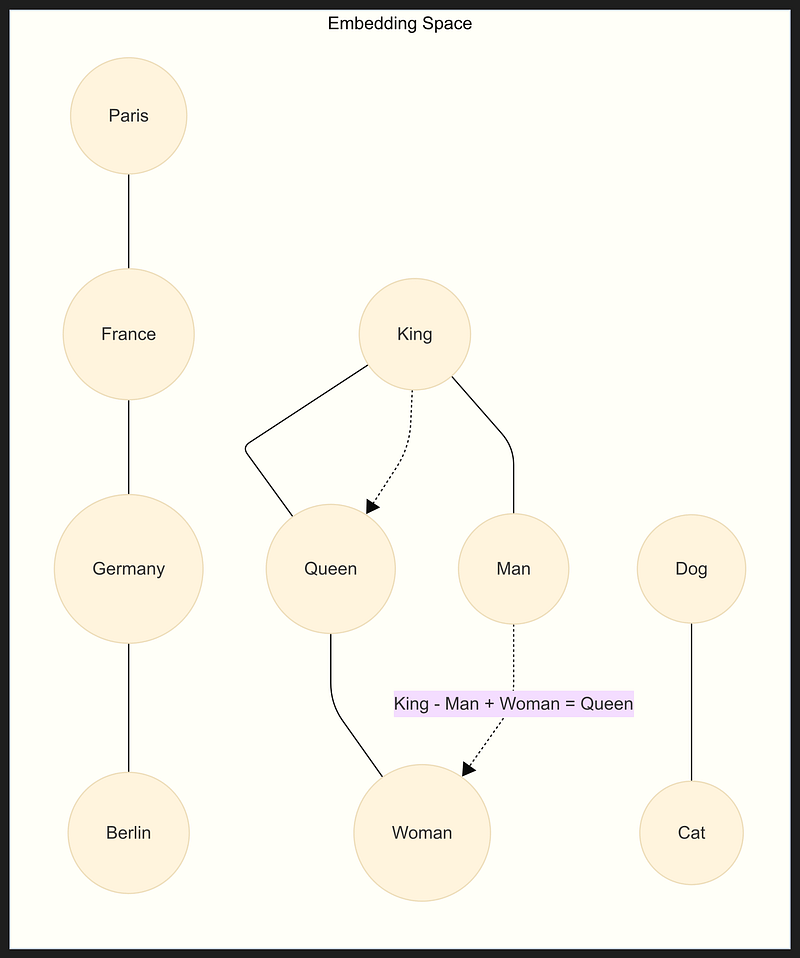
These vectors are what the model actually uses for everything: predicting the next token, finding patterns, and making analogies. In this geometric universe, arithmetic can do strange and beautiful things. There’s the classic example: take the embedding for "king", subtract the one for "man", add the one for "woman", and you land right next to "queen". The model didn’t learn this from a dictionary. It absorbed it by simply noticing how words travel together across countless sentences. Meaning, for a machine, it becomes a matter of location and direction.
In embedding space, “closeness” signals similarity. Paris and France huddle together; king and queen, man and woman, dog and cat—all find their neighbors not by definition, but by patterns learned from data. Analogies trace straight lines between points. (Image by Author)
So, while you see words, the model is busy navigating a swirling constellation of vectors, an invisible, shifting map of language where every token has a place.
Contextual Embeddings
Meaning in Motion
Early embeddings were one-size-fits-all. The word "bank" pointed to a single spot, no matter if you meant a riverbank or a bank loan. That was progress over bag-of-words, but still awkward. It’s like giving someone a single business card for every job they’ll ever have. Never quite the right fit.
Everything changed with contextual embeddings. Now, the model reads a whole sentence at once, and as it processes each token, it lets the company it keeps reshape its meaning. Suddenly, "bank" in "the bank raised rates" drifts toward finance, while “the river bank overflowed” tugs it into geography.
Picture it: you’re reading a sentence, and as each word arrives, your mental image shifts. The model does this, but with vectors (numbers adjusting on the fly, tuned by the sentence around them). By the final layer, every token’s vector is soaked in context. "Bank" doesn’t stand alone; it listens to its neighbors before picking a home.
This is the real breakthrough. Meaning isn’t fixed. It’s fluid, relational, and alive for just that moment. And that’s why transformers, the architecture behind GPT and friends, feel so much more human than anything that came before. They don’t just count words. They adapt, improvise, and remember, all in the language of numbers.
Beyond Words
Sentence Embeddings and Whole Thoughts
But language isn’t just tokens or even words in context. Sometimes, what we care about is the meaning of an entire sentence or the shape of a thought. That’s where sentence embeddings come in.
Imagine you’re sorting through customer reviews or trying to match a question to its best answer. You want a single “summary” for each chunk of text: a fingerprint that somehow captures the gist. The simplest trick is just to average all the token vectors for a sentence. But smarter models, like Sentence-BERT or those in the SentenceTransformers library, train themselves to spit out a vector that truly represents the whole idea.
What’s wild is how well this works. Two very different sentences, "An apple a day keeps the doctor away" and "Eating fruit daily is good for your health", end up as neighbors in this vector space because their meaning overlaps. A third sentence about the latest iPhone will land far away. Suddenly, you can search, cluster, or recommend, all by working with these dense, abstract vectors.
Here’s how this looks in practice:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["AI is eating the software world.",
"Software is eating the world, and now AI is eating software."]
embeddings = model.encode(sentences)
print(len(embeddings[0]), len(embeddings[1])) # each is 384-dimensional
Now, with just a few lines of code, you have a 384-number “meaning vector” for each sentence. You can compare, cluster, or search. No keywords needed, just the math of meaning.
Text embeddings have become the Swiss Army knife for modern language tasks. Need to find duplicate tickets? Rank answers by relevance? Cluster news articles by topic? It’s all embeddings, under the hood.
Embeddings Escape
From Word Vectors to Recommender Systems
Here’s where the story takes an unexpected turn. Embeddings didn’t stay locked in language for long. They broke out, and now they’re everywhere.
Think about your favorite music app. Every time you build a playlist, you’re stringing together songs in a sequence, almost like words in a sentence. Companies realized they could treat songs (or products, or users) as tokens and playlists as “sentences.” Feed that data into an embedding model, and suddenly you can recommend new artists by finding what’s nearby in this learned space.
That’s why, if you love Metallica, your app knows to nudge you toward Megadeth and Iron Maiden. They live close together, mathematically. The same trick works for e-commerce: people who buy hiking boots also pick up rain jackets and camp stoves, and now those items cluster in the shopping-verse. Even Google News used embeddings to surface stories that belong together.
This isn’t a technical curiosity. It’s become the connective tissue of the modern internet. Every time a system guesses what you’ll want next, it’s using embeddings, turning the chaos of history and behavior into a map of meaning.
Once you see it, you realize everything is an embedding now. Products, users, images, even code. The algorithm is always looking for closeness in some secret space, hoping to predict what fits, what belongs, and what comes next.
Bridging the Gap
Why Tokens and Embeddings Matter (and What Gets Lost)
Understanding tokens and embeddings isn’t just trivia for nerds. It’s the secret to demystifying how these machines “think,” and it exposes both their magic and their blind spots.
Start with the obvious: If you’re building with LLMs, knowing how tokenization works can save you real money and headaches. Prompt too long? It’s not the number of words that matters, but the number of tokens. A single misspelled word can eat up three or four tokens or turn "ChatGPT" into "Chat", "G", and "PT". Even a well-written prompt might split weirdly if you use a rare name or borrow a term from another language. The quirks add up: you pay for every token, and sometimes a shorter sentence in English actually burns more tokens than a longer paraphrase.
That’s the practical side. Then there’s the “why did my model output look so strange?” moments, like when it repeats a word, invents a new spelling, or splits a name in the middle. Most of these glitches are just the token system peeking through.
But the philosophical gap runs deeper. Embeddings don’t know things. They just record patterns. If "doctor" and "hospital" land close together in the vector space, it’s only because they travel together in text. There’s no grounding, no lived experience, no actual understanding. That’s why these models can riff on analogies but fail at basic common sense or hallucinate confident nonsense. They’re compressing the world into numbers, but the “why” behind each connection is always a ghost.
And those vectors are only as fair as the data that shaped them. If old biases and stereotypes linger in the training text, embeddings will reflect them, sometimes in unsettling ways. The infamous analogy where man : computer programmer :: woman : homemaker wasn’t a one-off bug. It’s a warning. The model soaks up the world as it is, flaws and all, and then bakes those patterns into the code.
Once you see this, you can’t unsee it. These models are powerful, but their strengths and failures are tangled up in the way they break language down and build it back up. The better we understand their hidden mechanics, the wiser and more careful we can be about what we trust, what we automate, and what we always double-check.
In the End
The Bridge and the Bargain
In the end, tokens and embeddings are the bridge between how humans talk and how machines compute. They’re a translation layer, sometimes clever, sometimes clumsy, where plenty is lost in crossing, but something new is also made possible.
LLMs have redefined “reading” and “writing” for machines. They take our words, rewrite them into numbers, and spin meaning from the math. It’s fragile, yes. A stray token can tip the whole output, and a warped embedding can echo bias, but it’s also astonishing in its resilience. Messy input, typos, even made-up words, and the system keeps going, improvising in its own strange tongue.
The next time you watch a chatbot reply, try to picture it: your words crumbling into tokens, flying off into a secret mathematical space, then reassembling as an answer, one piece at a time. If you understand this process, you see both the beauty and the limitations of the puppet show. You know when to marvel and when to look for the strings.
By learning the mechanics, you gain power. You become a better builder, a sharper critic, and a more honest partner to the tools you use. That’s the bargain. Not to worship the machine’s cleverness, but to keep asking, “What did we gain? And what did we lose in translation?”
V
Subscribe to our newsletter.
Become a subscriber receive the latest updates in your inbox.
You might also like
Aug 25
The End of the Magic Prompt
Good output is not a wish. It is systems work. We stitch steps into chains, add memory, let agents pick tools, and tune models until behavior matches intent. The magic prompt is over. Real craft is designing how the machine thinks, then teaching it.
6 min read
Aug 12
Prompt Engineering and the Illusion of Instruction
We think we’re giving orders. We’re steering a next-token engine. Prompts work when they mirror patterns the model has seen. Tiny phrasing changes flip outcomes. Guide with short roles, small examples, and simple formats. Verify. Cooperation, not command.
10 min read
Aug 11
What Makes a Senior Developer Senior?
Seniority isn’t a title. It’s how you work when it counts: choose the boring tool when it wins, ship with guardrails, teach without theater, cut complexity, and own outcomes after merge. Tradeoffs over tricks. Clarity over clever. Spotlight traded for team lift.
8 min read
Aug 09
Sorting Words, Clustering Thoughts
We sort words without thinking. Machines can't. They learn to draw boundaries and find themes: spam or not, tickets by topic. Use labels when you need decisions and clusters when you need discovery. Start there. Patterns come first, meaning follows.
8 min read
Aug 06
Inside the Clockwork of an AI’s Mind
Ask a question, get a fluent answer. Under the hood, no insight, just a fast loop picking the next token, guided by attention and a tiny memory. See the gears, not a ghost. When you learn the strings, you know when to trust it and when to steer.






Member discussion